
Graphical Abstract


A lightweight model based on series of ConvNets to recolor images for users with protanopia. Suitable for edge-end devices and small adjustments. Simple introduction for the field of Daltonization and visual recoloring to practical deep-learning frameworks.
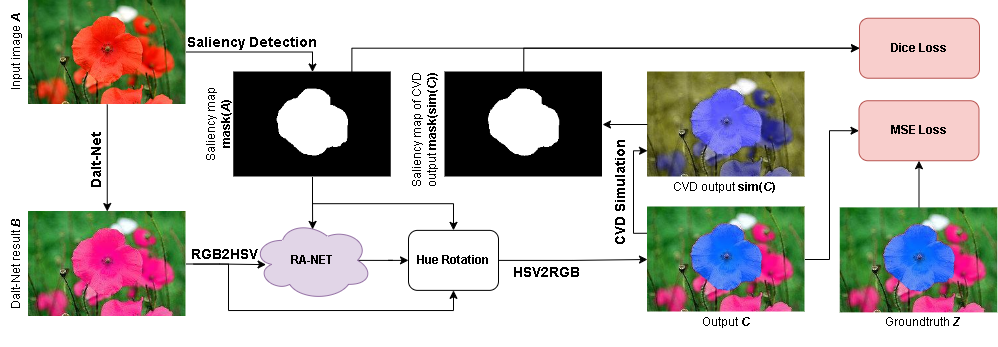
With new research in CVD recoloring, we have designed a new model to improve salient regions of images to reduce the visual fatigue that users with colorblindness may face. Suitable for cases where distinguishability is critical.
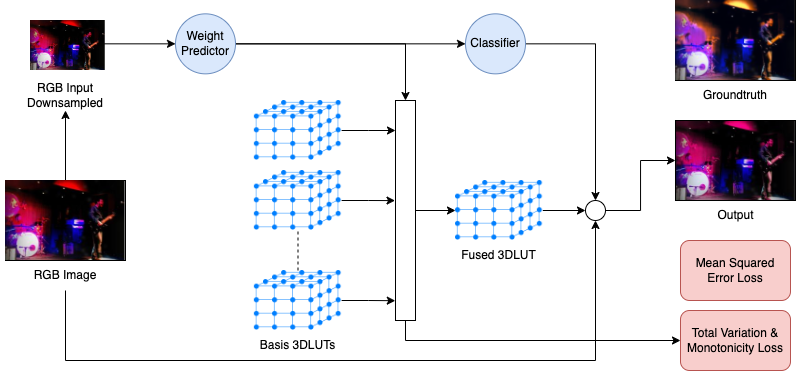
The new model brings in a wave of new data. Improving on Dalt-NET, a new transformer-dataset is introduced. In fact, the new architecture is that of a teacher-student model. A step in the future research, when transformational integrity is needed, but efficiency is even more critical.
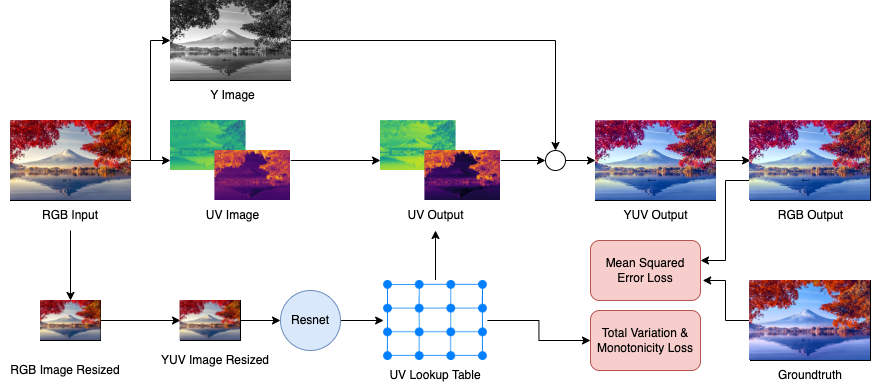
The flagship model builds on the work of all previous, combining the distillation top-down structure, custom datasets, and saliency. It introduces the chromaticity mapping-method, which is more efficient and learnable. Suitable for all types of recoloring cases, even beyond Color Vision Deficiency.
Color Vision Deficiency (color blindness) affects about 8% of men and 0.44% of women around the world. That's about 300 million people, all facing barriers in a world that is becoming increasingly digital, and thus visually-oriented. Unlike how people usually perceive it, CVD is not a single condition—it consists of a long, continuous spectrum of visual impairment.


When underlying genetics cause one type of photoreceptor from the eye to become inhibited or simply not be present, a range of EM wavelengths become lost. As color is essentially 3-dimensional (due to having 3 photoreceptors), this means that losing a photoreceptor will turn one's color perception into 2 dimensions, called dichromacy.
Translating into other color spaces, like LMS and YUV, this manifests in "confusion lines" which represent the lines of colors that dichromatic observers cannot distinguish. In the YUV color space, the intersection of the confusion lines is the "confusion point". This also means that the only color information that pure dichromats will get is the "angle" of the color with respect to the confusion point (when represented in YUV space). This helps represent and stabilize color spaces for the following process to enhance the images for the color blind—"Daltonization".




Another way of understanding dichromacy: the 2nd picture is the protanopic (red color-blind) simulation of the original color gamut (range) in the 1st. Note that the gamuts above (and any 2d gamuts) are a cross section of the entire color range of humans (as color is 3d!). However, in the 2d protanopic gamut, there is only 1 dimension represented as a point's distance from the confusion point becomes irrelevant. When the gamut is extended to 3d, there would only be 2 dimensions for protanopes.
Daltonization is the overarching method to recolor images to make them understandable for CVD individuals. In 2023, there were 4 criteria that I defined: a) Contrast maintained/improved in the Daltonized image, b) Context-based consistency of colors retained across different images, c) Context-based naturalness or reason of color of real objects demonstrated in Daltonized images, d) Speed of algorithm able to run in real-time.
A common method of Daltonization is to rotate the "hue" of color clusters around the white point (which has no hue). The white point is inside the color gamut, which means that most colors will rotate to another color that is also inside the gamut. For protanopia, red usually rotates towards blue. This means that the original red, which is essentially black for CVD observers, turns to magenta for normal observers but blue for CVD observers.


However, this type of static hue-rotation brings many disadvantages. For one, while hue rotation can bring distinguishability to reds in the original image, it will certainly turn previously distinguishable colors or objects no longer such. Additionally, maybe a blue apple wouldn't look too nice in the eyes of CVD observers. They would likely prefer a more muted color for objects that is consistent with what the it looks like in the real world around them. Thus, in a newer method, each color cluster is rotated differently, in order to displace them from being on the same confusion line. This is shown in the adjacent image.
Building on this, an even newer study used Generative Adversarial Networks (yes, deep learning!) in order to represent Daltonization transformations. The authors designed a mini-recoloring algorithm named an "Improved Octree Quantification Method" which similar to the method in the above paragraph, and combined it with another study's algorithm (a fixed hue-rotation) in order to create a dataset, which then trained on several image-to-image GAN networks. However, the issue here is that GANs are slowww... especially if you are applying it on a 30 FPS video.

In 2024, an additional objective, saliency, was captured from literature review. There are now five different objectives that pertain to practical usage, quality of life, and scalability purposes for InnoColor:
InnoColor v3 consists of a chromaticity-mapping architecture that aims towards knowledge distillation. There are 3 versions of the deep-learning framework, each employing varied methods that enabled various objectives. Check them out at the top of the page!
In terms of objectives met—InnoColor surpasses all previous methods, save the distillation data source, in cross-the-board performance. Check some of InnoColor's result comparisons here
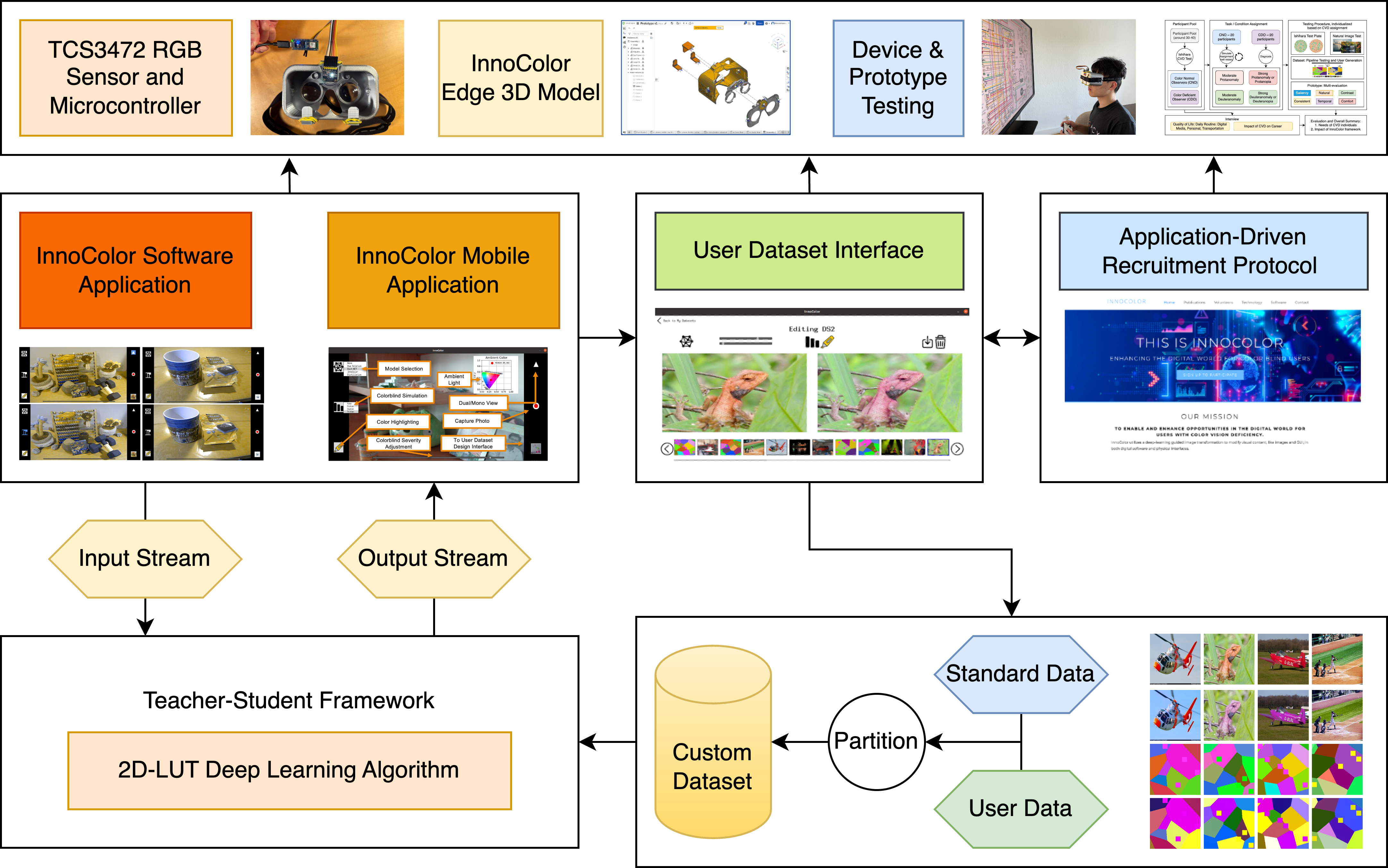
InnoColor utilizes a deep-learning guided image transformation to modify visual content, like images, video, and GUI, in both digital software and physical interfaces.